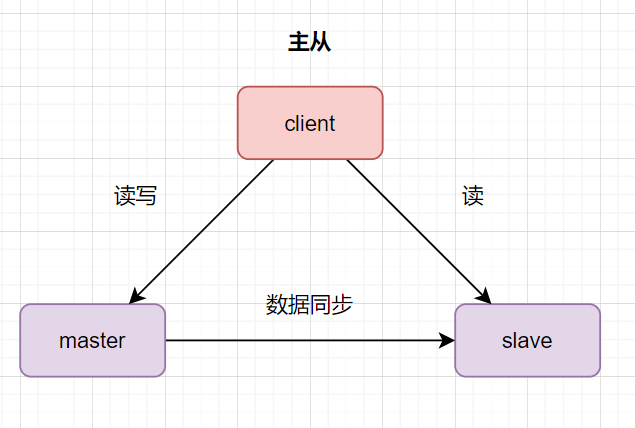
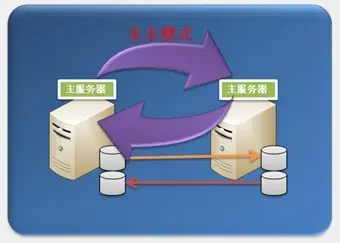
Nginx双机热备-主从模式
Nginx负载均衡技术对于一个网站尤其是大型网站的web服务器集群来说是至关重要的!做好负载均衡架构,可以实现故障转移和高可用环境,避免单点故障,保证网站健康持续运行。技术参考
双机高可用一般是通过虚拟IP(飘移IP)方法来实现的,基于Linux/Unix的IP别名技术。
双机高可用方法目前分为两种:
- 双机主从模式:即前端使用两台服务器,一台主服务器和一台热备服务器,正常情况下,主服务器绑定一个公网虚拟IP,提供负载均衡服务,热备服务器处于空闲状态;当主服务器发生故障时,热备服务器接管主服务器的公网虚拟IP,提供负载均衡服务;但是热备服务器在主机器不出现故障的时候,永远处于浪费状态,对于服务器不多的网站,该方案不经济实惠。
- 双机主主模式:即前端使用两台负载均衡服务器,互为主备,且都处于活动状态,同时各自绑定一个公网虚拟IP,提供负载均衡服务;当其中一台发生故障时,另一台接管发生故障服务器的公网虚拟IP(这时由非故障机器一台负担所有的请求)。这种方案,经济实惠,非常适合于当前架构环境。配置参考
keepalived可以认为是VRRP协议在Linux上的实现,主要有三个模块,分别是core、check和vrrp。
core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。
check负责健康检查,包括常见的各种检查方式。
vrrp模块是来实现VRRP协议的。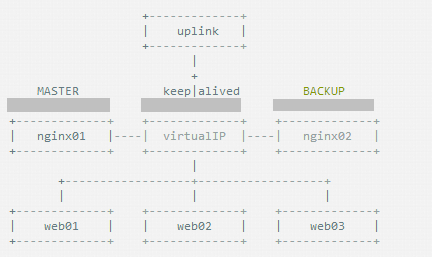
keepalived核心概念
- 通过选举投票,决定谁是主节点谁是备节点(选举)
- 如果Master故障,Backup自动接管,那么Master恢复后会夺权吗(抢占试、非抢占式)
- 两台服务器都认为自己是master,那么会出现一个故障(脑裂)
环境准备
操作系统:centos7.6
master机器(master-node):10.11.7.231
slave机器(slave-node):10.11.7.232
虚拟IP(VIP):10.11.7.235 负载均衡器上配置的域名都解析到这个VIP上
设置主机名, 关闭SElinux,关闭防火墙(暂时关闭)
1 | [root@master-node ~]# hostnamectl set-hostname master-node |
配置防火墙
1 | # 启用ip转发 |
环境安装
部署 nginx-1.20.2 和 keepalive-2.2.7服务 (master-node和slave-node两台服务器上的安装操作完全一样)
可选择编译安装或者yum安装,注意版本号;
监听存活脚本
此脚本必须在keepalived服务运行的前提下才有效!如果在keepalived服务先关闭的情况下,那么nginx服务关闭后就不能实现自启动了。
该脚本检测ngnix的运行状态,并在nginx进程不存在时尝试重新启动ngnix,如果启动失败则停止keepalived,准备让其它机器接管。
1 | [root@master-node keepalived]# vi /etc/keepalived/check_nginx.sh |
keepalived配置
keepalived 配置参考
两节点的上联交换机允许组播,采用组播模式(默认)
组播可能导致地址冲突问题,当在同一个局域网内部署了多组keepalived服务器时,可能会发生高可用接管的严重故障问题。 因为keepalived高可用功能是通过VRRP协议实现的,VRRP协议默认通过IP多播的形式实现高可用对之间的通信,如果同一个局域网内存在多组Keepalived服务器对,就会造成IP多播地址冲突问题,导致接管错乱. 不同组的keepalived都会使用默认的224.0.0.18作为多播地址。此时的解决办法是,在同组的keepalived服务器所有的配置文件里指定独一无二的多播地址,配置如下:
mcast_src_ip 发送多播包的地址,如果不设置默认使用绑定网卡的primary ip两节点的上联交换机禁用了组播,则只能采用vrrp单播通告的方式,配置如下:
unicast_src_ip xx.xx.xx.xx 本机
unicast_peer {
xx.xx.xx.xx 其他
}
配置参考示例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39[root@master-node ~]# vi /etc/keepalived/keepalived.conf
! Configuration File for keepalived #全局定义
global_defs {
notification_email { #指定keepalived在发生事件时(比如切换)发送通知邮件的邮箱
ops@wangshibo.cn #设置报警邮件地址,可以设置多个,每行一个。 需开启本机的sendmail服务
tech@wangshibo.cn
}
notification_email_from ops@wangshibo.cn #keepalived在发生诸如切换操作时需要发送email通知地址
smtp_server 127.0.0.1 #指定发送email的smtp服务器
smtp_connect_timeout 30 #设置连接smtp server的超时时间
router_id master-node #运行keepalived的机器的一个标识,通常可设为hostname。故障发生时,发邮件时显示在邮件主题中的信息。
}
vrrp_script chk_http_port { #检测nginx服务是否在运行。有很多方式,比如进程,用脚本检测等等
script "/etc/keepalived/check_nginx.sh" #这里通过脚本监测
interval 2 #脚本执行间隔,每2s检测一次
weight -5 #脚本结果导致的优先级变更,检测失败(脚本返回非0)则优先级 -5
fall 2 #检测连续2次失败才算确定是真失败。会用weight减少优先级(1-255之间)
rise 1 #检测1次成功就算成功。但不修改优先级
}
vrrp_instance VI_1 { #keepalived在同一virtual_router_id中priority(0-255)最大的会成为master,也就是接管VIP,当priority最大的主机发生故障后次priority将会接管
state MASTER #指定keepalived的角色,MASTER表示此主机是主服务器,BACKUP表示此主机是备用服务器。注意这里的state指定instance(Initial)的初始状态,就是说在配置好后,这台服务器的初始状态就是这里指定的,但这里指定的不算,还是得要通过竞选通过优先级来确定。如果这里设置为MASTER,但如若他的优先级不及另外一台,那么这台在发送通告时,会发送自己的优先级,另外一台发现优先级不如自己的高,那么他会就回抢占为MASTER
interface em1 #指定HA监测网络的接口。实例绑定的网卡,因为在配置虚拟IP的时候必须是在已有的网卡上添加的
mcast_src_ip 103.110.98.14 # 发送多播数据包时的源IP地址,这里注意了,这里实际上就是在哪个地址上发送VRRP通告,这个非常重要,一定要选择稳定的网卡端口来发送,这里相当于heartbeat的心跳端口,如果没有设置那么就用默认的绑定的网卡的IP,也就是interface指定的IP地址
virtual_router_id 51 #虚拟路由标识,这个标识是一个数字,同一个vrrp实例使用唯一的标识。即同一vrrp_instance下,MASTER和BACKUP必须是一致的
priority 101 #定义优先级,数字越大,优先级越高,在同一个vrrp_instance下,MASTER的优先级必须大于BACKUP的优先级
advert_int 1 #设定MASTER与BACKUP负载均衡器之间同步检查的时间间隔,单位是秒
nopreempt # 非抢占模式 默认:抢占模式
authentication { #设置验证类型和密码。主从必须一样
auth_type PASS #设置vrrp验证类型,主要有PASS和AH两种
auth_pass 1111 #设置vrrp验证密码,在同一个vrrp_instance下,MASTER与BACKUP必须使用相同的密码才能正常通信
}
virtual_ipaddress { #VRRP HA 虚拟地址 如果有多个VIP,继续换行填写
103.110.98.20
}
track_script { #执行监控的服务。注意这个设置不能紧挨着写在vrrp_script配置块的后面(实验中碰过的坑),否则nginx监控失效!!
chk_http_port #引用VRRP脚本,即在 vrrp_script 部分指定的名字。定期运行它们来改变优先级,并最终引发主备切换。
}
}
master-node节点的keepalived配置,并重启keepalived服务
1 | [root@master-node ~]# vi /etc/keepalived/keepalived.conf |
slave-node节点的keepalived配置,并重启keepalived服务
1 | [root@slave-node ~]# vi /etc/keepalived/keepalived.conf |
VIP漂移验证
keepalived只检测本机和他机keepalived是否正常并实现VIP的漂移,而如果本机nginx出现故障不会则不会漂移VIP。
keepalived默认就是抢占模式
所以编写脚本来判断本机nginx是否正常,如果发现NginX不正常,重启之。等待3秒再次校验,仍然失败则不再尝试,关闭keepalived,其他主机此时会接管VIP
重新启动主服务器上的keepalived,发现主服务器又重新接管了VIP,此时slave机器上的VIP已经不在了。
keepalived配置非抢占模式
master故障—>backup顶上—>master恢复不抢占vip—>backup拥有vip继续工作
1、两个节点的state都必须配置为BACKUP(官方建议)
2、两个节点都在vrrp_instance中添加nopreempt参数(其实优先级高的配置nopreempt参数即可)
3、其中一个节点的优先级必须要高于另外一个节点的优先级。
注意:要使nopreempt参数起作用,初始状态不能是MASTER。
在优先级高的节点的 vrrp_instance 中 配置 nopreempt ,当它异常恢复后,即使它 prio 更高也不会抢占,这样可以避免正常情况下做无谓的切换
以上可以做到利用脚本检测业务进程的状态,并动态调整优先级从而实现主备切换。
1 | [root@master-node ~]# ip addr |